前回のECHONET Lite制御に引き続き、こちらも前々からやってみたかったことです。
音声制御自体は前にも音声認識エンジンのJuliusを使ってやったことがあるのですが、あれはラピロに直接接続した有線マイクを使って、ラピロ本体で音声認識をすることで実現していました。
こちらは、マイクと音声認識の部分が、どちらもスマホ側に乗っかっているところがポイントです。動画ではタブレットにハンズフリー的にラピロに話しかけていますが、実際はスマホを電話をかけるように(=耳にあてるように)持って話しかけてもいいのです。そのスタイルの方が、マイクに面と向かって話しかけるよりは、自然に音声制御を利用できるのではないかなーと思います。
ブラウザでの音声認識には、Web Speech APIを利用しています。自分が試したところでは、iPhoneではSafariもChromeもWeb Speech APIには対応していなかったので、デモではAndroid端末(Nexus 7)のChromeブラウザ上でテストしています。
なお、自分はHTMLとCSSには疎いので、音声認識用のWebページは勉強がてらBootstrapを使って作ってみました。今回はとてもシンプルなページにしたのであまり意味がないですが、ここからもう少し情報量増やしていくときには、レスポンシブウェブ対応が簡単になる。。。と思います。
実装方法については、前回のECHONET Lite対応ができれば、ほぼできたようなものです。さらにその前のLogbar Ring制御も、理屈は同じです。あんまり技術的に突っ込んだ知識は持っていないので、自分が比較的簡単に使えそうなモノを組み合わせて作り上げていったので、あんまり綺麗な構成にはなっていないと思います。が、裏を返せば、あんまり技術に詳しくなくてもここまではやれます、とも言えると思います。少しはニーズがあるかもしれないので、少しずつまとめていこうと思います。
ということで、ちょっと長い休みがとれたので、自分がこの一年ぼんやりと考えていた「やりたかったこと」を一気にやってしまいました。ソフト的には、後はどれだけ綺麗に作り込んでいくか、というところなので、少しずつハード的な拡張の方にシフトしていこうかなーと思っています。Arduinoとの連携とか、3Dプリンタでの追加パーツの造形とか。
あ、でも、自分はまだ持っていないのですが、スマホはそろそろAndroid WearとかApple Watchとかのウェアラブルデバイスとの連携が本格化してきそうなんですよね。ということは、今回の作例をもう少し発展させて、腕時計に話しかけて操作するというジャイアントロボ的な操作の仕方も、近いウチにできるようになるかもしれない。。。とか考えると、ワクワクしますね。男の子なもんで。
(2015/8/5 追記)
この実装のコードを公開してほしいとのご連絡をいただきました。なぜ公開していなかったかというと、結構面倒な仕組みになっていたから … です。頑張って要点だけ拾い集めてみますが、どこか抜けがあったらすみません。
始めに、全体像を確認しておきます。
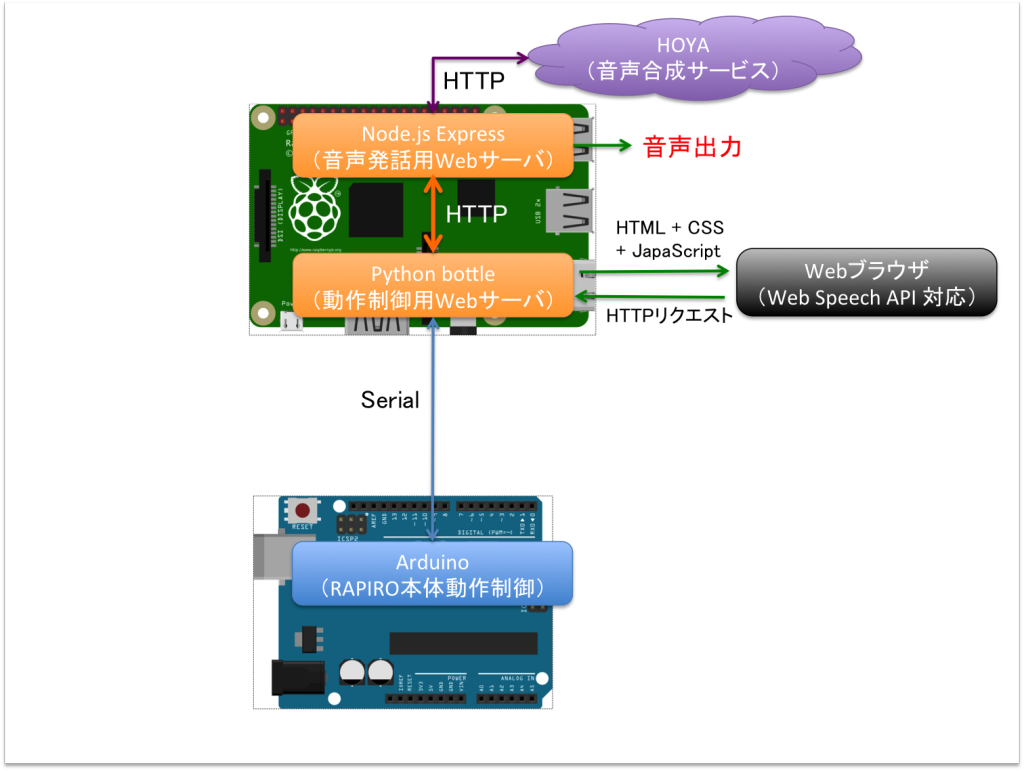
この仕組みの中核にあるのは、Pythonのbottleフレームワークを使ったWebサーバです。なので、まずはbottleを使えるようにしておいてください。pipでインストールするのが標準みたいですが、bottle.pyを持ってくるだけでも良いかもしれません。
さて、まずはWebブラウザで表示させるhtmlから。これは抜粋ではなく、全文です。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link href="css/bootstrap.min.css" rel="stylesheet">
<title>Talk with RAPIRO</title>
</head>
<body>
<div class="container">
<div class="panel panel-default">
<div class="panel-heading">
<h1>Talk with RAPIRO</h1>
<p>by Web Speech API</p>
</div>
<div class="panel-body text-center">
<input type="image"
src="img/microphone.jpg"
width="300px"
height="300px"
id="on_off_button">
<p>
<b id="on_off_message">
↑ Touch to START talking with RAPIRO ↑
</b>
</p>
<p id="status_message">
Speech Recognition is NOT valid.
</p>
<div class="form-group">
<textarea name="recognized_text"
id="recognized_text"
rows="6"
class="form-control"></textarea>
</div>
<button type="submit"
class="btn btn-default"
id="clear_button">
Clear
</button>
</div>
<div class="panel-footer text-center">
<p>©make-muda.weblike.jp</p>
</div>
</div>
</div>
<script type="text/javascript" src="js/jquery.min.js"></script>
<script type="text/javascript" src="js/bootstrap.min.js"></script>
<script type="text/javascript" src="js/web_speech.js"></script>
</body>
</html>ここはUIの見た目だけの問題で、特に難しいことはしていません。Bootstrapを使っていますので、それは別途ダウンロードして利用できるようにしてください。あと、中央のイラスト(microphone.jpで参照しているもの)はこちらから拝借させいただいています。
それから、音声認識のメインとなるjsファイルです。こちらも全文です。
var recognizing;
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = false;
recognition.lang = "ja-JP";
recognizing = false;
var final_transcript = "";
recognition.onstart = function (event) {
console.log("Recognize on start");
recognizing = true;
$('#on_off_message').text("↑ Touch to STOP talking with RAPIRO ↑");
$('#status_message').text("Speech Recognition is valid now.");
};
recognition.onspeechstart = function (event) {
console.log("Recognize on speech start");
};
recognition.onspeechend = function (event) {
console.log("Recognize on speech end");
};
recognition.onend = function (event) {
console.log("Recognize on end");
recognizing = false;
$('#on_off_message').text("↑ Touch to START talking with RAPIRO ↑");
$('#status_message').text("Speech Recognition is NOT valid now.");
clear();
};
recognition.onerror = function (event) {
console.log("Recognize on error:" + event.error);
};
recognition.onresult = function (event) {
console.log("Recognized!");
var interim_transcript = "";
var result_script = "";
for (var i = event.resultIndex; i < event.results.length; ++i) {
result_script = event.results[i][0].transcript;
result_script = result_script.replace(/^\s+/g, "");
if (event.results[i].isFinal) {
console.log("FINAL: " + result_script);
final_transcript += result_script;
// —— HTTP Connection ——
$.get(
"http://192.168.24.50:10080/v1/robots/rapiro/control/talk",
{ text: result_script },
function (data) {
console.log(data);
}
);
} else {
console.log("Not FINAL: " + result_script);
interim_transcript += result_script;
}
}
$('#recognized_text').val(final_transcript);
};
$('#on_off_button').on('click', function (e) {
console.log("Toggle Speech Recognition ON/OFF.");
if (recognizing) {
recognition.stop();
} else {
recognition.start();
}
});
$('#clear_button').on('click', function (e) {
clear();
});
function clear() {
console.log("Clear Recognized Text.");
final_transcript = "";
$('#recognized_text').val("");
}ここではWeb Speech APIでの音声認識の結果を、HTTPのGETリクエストの引数にして、同じWebサーバの別URL(”http://192.168.24.50:10080/v1/robots/rapiro/control/talk?text=…”)に投げています。
ここまで作成したHTML+JavaScriptに、例えば”http://192.168.24.50:10080/v1/robots/rapiro/talk.html”でアクセスしたい場合には、bottleを使ったサーバ用プログラムで以下のように記述して、静的ページを表示する必要があります。
from bottle import route, request, response, run, hook, static_file
@hook(‘after_request’)
def enable_cors():
response.content_type = ‘application/json’
response.headers[‘Access-Control-Allow-Origin’] = ‘http://192.168.24.50’
@route(‘/v1/robots/rapiro/<filename:path>’)
def send_static(filename):
return static_file(filename, root=’/home/pi/bottle’)
run(host=’192.168.24.50′, port=10080, debug=True)不要なimportや hookがあるかもしれませんが、ご了承ください。
次に、上記のサーバ用プログラムに、web_speech.jsの中で投げていたGETリクエスト先(”http://192.168.24.50:10080/v1/robots/rapiro/control/talk?text=…”)のルーティングを追加すると、こんな感じになります。
# coding: utf-8
from bottle import route, request, response, run, hook, static_file
import serial
com = serial.Serial('/dev/ttyAMA0', 57600, timeout=10)
@hook('after_request')
def enable_cors():
response.content_type = 'application/json'
response.headers['Access-Control-Allow-Origin'] = 'http://192.168.24.50'
@route('/v1/robots/rapiro/<filename:path>')
def send_static(filename):
return static_file(filename, root='/home/pi/bottle')
def control_response_json(value):
obj = {'control': value}
return json.dumps(obj)
@route('/v1/robots/rapiro/control/init')
def control_init():
com.write("#M0")
time.sleep(2)
com.write("#PR000G000B000T010")
time.sleep(1)
com.write('#S')
return control_response_json("init")
def talk_response_json(status_code, text):
obj = {'status_code': status_code, 'text': text}
return json.dumps(obj)
@route('/v1/robots/rapiro/control/talk')
def control_talk():
text = request.query.text
print "Control Server: text:" + text
com.write("#PS02A120T010")
res = requests.get('http://localhost:3000/v1/robots/rapiro/talk?text=' + text)
print 'Control Server received from Talk Server:%d' % res.status_code
#print res.text
return talk_response_json(res.status_code, res.text)
run(host='192.168.24.50', port=10080, debug=True)追加したルーティングの中でArduinoとシリアル通信をすることになるので、サーバプログラムの冒頭でserialをインポートして、事前にシリアル通信(com)を開いています。
“/v1/robots/rapiro/control/init”の方のルーティングは、後で出てきますが、ラピロを初期状態(静止状態)に戻すためのURLです。
“/v1/robots/rapiro/control/talk”の方が、先ほどのJavaScriptからのリクエストをさばくルーティングで、右手を上げて(com.write(“PS02A120T010”))から、さらに同じ端末内の別ポート(3000番)で待ち受けている、node.jsで書かれたWebサーバに対してリクエストを投げています。
ここで注意なのですが、この「node.jsで書かれたWebサーバへの更なるリクエスト」は、別に必須じゃありません。ここでリクエストを投げる代わりに、音声認識結果の文字列の中身を見て、それに応じて適切な音声ファイルの再生と、com.write(“PS02A120T010”)のようなラピロの動作を決めるシリアル通信を実行すれば、それで「ラピロが音声を認識して、それに応じた動作をとる」という機能は実現できます。トップの動画デモも、その方法で実現可能です。
こんな別サーバを使う形になっているのは、私の変なこだわりによるもので、「(単純なタイマーではなく)ラピロがちゃんと喋り終わるのを待ってから腕を下ろす」というのをやりたくて、そのためには、自分の技術力ではこの形(node.jsのWebサーバと組み合わせる形)でしか実現できなかったからです。音声再生が終わるときに発行されるイベントの中で、ラピロを静止状態に戻すためのURLを叩くようにしているのです。
ということで、一応受けて側のnode.jsのソースも載せておきますが、先に述べたとおり、簡単な音声操作をやりたいだけなら、ここまでやらなくてもよいですし、今ならもっと良い方法もあるかもしれません。
var express = require('express');
var request = require('request');
var VoiceText = require('voicetext');
var fs = require('fs');
var app = express();
var voice = new VoiceText('xxxxxxxxxxxxxxxxxx');
var spawn = require('child_process').spawn;
var Phrases = {
"ラピロ": "phrases/serve_yes.wav",
"はじめまして": "phrases/nice_to_meet_you.wav",
"おはよう": "phrases/good_morning.wav",
"こんにちは": "phrases/hello.wav",
"おやすみなさい": "phrases/good_night.wav",
"いってきます": "phrases/have_a_nice_day.wav",
"ただいま": "phrases/how_was_your_day.wav",
"お疲れ様": "phrases/good_job.wav",
"ねぇ": "phrases/serve_yes.wav",
"ねぇねぇ": "phrases/serve_yes.wav",
"名前は": "phrases/my_name.wav",
"元気": "phrases/im_fine.wav",
"かわいいね": "phrases/thanks.wav",
"それはできません": "phrases/cannot_execute.wav",
"すみません、もう一度仰ってください": "phrases/pardon.wav"
};
app.get('/v1/robots/rapiro/talk', function (req, res) {
var text = req.query.text ? req.query.text : "";
console.log("Talk Server: " + text);
if (text in Phrases) {
console.log("Play pre-set voice.");
playVoice(text, Phrases[text]);
res.send(text);
return;
}
var speaker = req.query.speaker ? req.query.speaker : voice.SPEAKER.HARUKA;
var emotion = req.query.emotion ? req.query.emotion : 'none';
var emotion_level = req.query.emotion_level ? req.query.emotion_level : voice.EMOTION_LEVEL.LOW;
var pitch = req.query.pitch ? req.query.pitch : 100;
var speed = req.query.speed ? req.query.speed : 100;
var volume = req.query.volume ? req.query.volume : 100;
if (emotion != 'none') {
voice.emotion(emotion)
.emotion_level(emotion_level);
}
voice.speaker(speaker)
.pitch(pitch)
.speed(speed)
.volume(volume)
.speak(text, function (e, buf) {
return fs.writeFile('./temp.wav', buf, 'binary', function (e) {
if (e) {
return console.error(e);
}
playVoice(text, "temp.wav");
});
});
res.send(text);
});
var server = app.listen(3000, function () {
var host = server.address().address;
var port = server.address().port;
console.log('Example app listening at http://%s:%s', host, port);
});
var playVoice = function (text, option, path) {
console.log("Play file:" + path);
var aplay = spawn('aplay', [path]);
aplay.stdout.on('data', function (data) {
console.log("stdout: Start playing!");
});
aplay.stderr.on('data', function (data) {
console.log("stderr: Start playing!");
});
aplay.on('exit', function (code) {
console.log("Finish playing!");
url = 'http://192.168.24.50:10080/v1/robots/rapiro/control/init';
request(url, function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log("From Talk Server to Control Server SUCCESS");
} else {
console.log("From Talk Server to Control Server Error: " + response.statusCode);
}
});
});
};ちなみに、このソースは特定の言葉に対しては特定の音声ファイルを再生するようになっていますが、未知の言葉が届いた場合は、それをHOYAの音声合成APIを使ってオウム返しするようなプログラムになっています。
以上です。元記事を書いたときの環境が完璧には残っていなくて、現状あるものから復元する形になったので、うまく動いてくれないかもしれませんが、何かしらの参考になるようでしたら幸いです。






コメント
コメント一覧 (4件)
こんにちは!いつも楽しく拝見させて頂いてます(^^)
この音声認識サイトのコードを公開していただけると、助かります!(T_T)
いつもご覧いただきありがとうございますm(_ _)m
申し訳ないことに、当時の環境が完全には残っていなかったので、
いろいろ復元しながらの公開になってしまいました。
もし動かなかったら、申し訳ありませんm(_ _)m
それでも何かしらの参考になるようでしたら、幸いです。
[…] RAPIRO(ラピロ)をスマホで音声制御する […]
[…] そんなわけなので、過去には別の手段として、Web Speech APIを使ったWebアプリに音声認識を任せる、というのもやってみました。音声認識は天下のGoogle様のサーバに任せてしまう、という […]