Raspberry Pi 2 x 4台でHadoopの完全分散モードを動作させる 後編

前回は事前準備だけで終わってしまいました。今回でHadoop本体の設定からMapReduceのサンプル動作確認まで一気にやってしまいます。
ちなみに、Hadoopを動かすにはJavaが必要なのですが、最新のRaspbian OSには初めからJavaが入っているので、今回はそれをそのまま使うようにしています。
Hadoopのインストール
4台すべてのRaspberry Piで実行します。
Hadoop本家のダウンロードサイトのリンクを参照して、最新版のバイナリファイルを落としてきます。ここでは2.7.1を利用します。
pi > $ wget http://ftp.tsukuba.wide.ad.jp/software/apache/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz pi > $ tar xzvf hadoop-2.7.1.tar.gz pi > $ sudo mv hadoop-2.7.1 /usr/share/. pi > $ sudo ln -s /usr/share/hadoop-2.7.1 /usr/share/hadoop
落としてきたものを解凍して、移動させます。シンボリックリンクにしているのは、後々Hadoopのバージョンが上がったときに簡単に切り替えられるようにするためです。
それから、後々必要になるディレクトリも作成しておきます。
pi > $ sudo mkdir /usr/share/hdfs pi > $ sudo mkdir /usr/share/hdfs/namenode pi > $ sudo mkdir /usr/share/hdfs/datanode pi > $ sudo mkdir /usr/share/hdfs/logs pi > $ sudo chown -R hdfs:users /usr/share/hdfs/namenode pi > $ sudo chown -R hdfs:users /usr/share/hdfs/datanode pi > $ sudo chown -R hdfs:users /usr/share/hdfs/logs pi > $ sudo mkdir /usr/share/yarn pi > $ sudo mkdir /usr/share/yarn/logs pi > $ sudo chown -R yarn:users /usr/share/yarn pi > $ sudo mkdir /usr/share/mapred pi > $ sudo mkdir /usr/share/mapred/logs pi > $ sudo chown -R mapred:users /usr/share/mapred
クライアント用Raspberry Piではディレクトリの作成は不要かもしれませんが、一応やっておきます。
環境変数の設定
ホスト名:master01のRaspberry Piのみで実行します。
Hadoop実行用の環境変数の設定ファイル”hadoop-layout.sh”を作成します。
pi > $ vim /usr/share/hadoop/libexec/hadoop-layout.sh # Set all Hadoop paths export JAVA_HOME=/usr/lib/jvm/jdk-8-oracle-arm-vfp-hflt export PATH=$PATH:$JAVA_HOME/bin export HADOOP_PREFIX=/usr/share/hadoop export HADOOP_HOME=$HADOOP_PREFIX export HADOOP_COMMON_HOME=$HADOOP_PREFIX export HADOOP_HDFS_HOME=$HADOOP_PREFIX export HADOOP_MAPRED_HOME=$HADOOP_PREFIX export HADOOP_YARN_HOME=$HADOOP_PREFIX export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop export HADOOP_LOG_DIR=/usr/share/hdfs/logs export HADOOP_MAPRED_LOG_DIR=/usr/share/mapred/logs export YARN_LOG_DIR=/usr/share/yarn/logs
なお、作成した”hadoop-layout.sh”の他のマシンへのコピーは、他の設定ファイルと一緒に最後にまとめて実施するので、ここはそのまま先に進んでください。
hdfs-site.xmlの設定
ホスト名:master01のRaspberry Piのみで実行します。
HDFSの設定ファイル”/usr/share/hadoop/etc/hadoop/hdfs-site.xml”を編集します。
pi > $ vim /usr/share/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/share/hdfs/namenode</value>
<description>Path on the local filesystem where the NameNode stores the namespace and transaction logs persistently.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/share/hdfs/datanode</value>
<description>Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks.</descript
ion>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>master01:50090</value>
<description>The secondary namenode http server address and port.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
</configuration>
今回はスレーブが2台しかないので、レプリケーションの値は2にしています。
core-site.xmlの編集
ホスト名:master01のRaspberry Piのみで実行します。
Hadoopの設定ファイル”/usr/share/hadoop/etc/hadoop/core-site.xml”を編集します。
pi > $ vim /usr/share/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master01/</value>
<description>NameNode URI</description>
</property>
</configuration>
yarn-site.xmlの設定
ホスト名:master01のRaspberry Piのみで実行します。
YARNの設定ファイル”/usr/share/hadoop/etc/hadoop/yarn-site.xml”を編集します。
pi > $ vim /usr/share/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master01</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
mapred-site.xmlの設定
ホスト名:master01のRaspberry Piのみで実行します。
MapReduceの設定ファイル”/usr/share/hadoop/etc/hadoop/mapred-site.xml”を編集します。これはテンプレートファイルをコピーしたものを使っていきます。
pi > $ cp /usr/share/hadoop/etc/hadoop/mapred-site.xml.template /usr/share/hadoop/etc/hadoop/mapred-site.xml pi > $ vim /usr/share/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.tracker.address</name>
<value>master01</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>256</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx358m</value>
</property>
<property>
<name>mapreduce.map.cpu.vcores</name>
<value>1</value>
<description>The number of virtual cores required for each map task.</description>
</property>
<property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>1</value>
<description>The number of virtual cores required for each map task.</description>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>256</value>
<description>Larger resource limit for maps.</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx358m</value>
<description>Heap-size for child jvms of maps.</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>256</value>
<description>Larger resource limit for reduces.</description>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx358m</value>
<description>Heap-size for child jvms of reduces.</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master01:10020</value>
</property>
</configuration>
設定ファイルのコピー
ホスト名:master01のRaspberry Piのみで実行します。
ここまで作成した5つの設定ファイル
- hadoop-layout.sh
- hdfs-site.xml
- core-site.xml
- yarn-site.xml
- mapred-site.xml
を、他のマシンに一気にコピーするためのスクリプトを作成します。
pi > $ vim copy-config.sh #!/bin/bash scp -p /usr/share/hadoop/libexec/hadoop-layout.sh pi@client00:/usr/share/hadoop/libexec/hadoop-layout.sh scp -p /usr/share/hadoop/etc/hadoop/core-site.xml pi@client00:/usr/share/hadoop/etc/hadoop/core-site.xml scp -p /usr/share/hadoop/etc/hadoop/hdfs-site.xml pi@client00:/usr/share/hadoop/etc/hadoop/hdfs-site.xml scp -p /usr/share/hadoop/etc/hadoop/yarn-site.xml pi@client00:/usr/share/hadoop/etc/hadoop/yarn-site.xml scp -p /usr/share/hadoop/etc/hadoop/mapred-site.xml pi@client00:/usr/share/hadoop/etc/hadoop/mapred-site.xml scp -p /usr/share/hadoop/libexec/hadoop-layout.sh pi@slave01:/usr/share/hadoop/libexec/hadoop-layout.sh scp -p /usr/share/hadoop/etc/hadoop/core-site.xml pi@slave01:/usr/share/hadoop/etc/hadoop/core-site.xml scp -p /usr/share/hadoop/etc/hadoop/hdfs-site.xml pi@slave01:/usr/share/hadoop/etc/hadoop/hdfs-site.xml scp -p /usr/share/hadoop/etc/hadoop/yarn-site.xml pi@slave01:/usr/share/hadoop/etc/hadoop/yarn-site.xml scp -p /usr/share/hadoop/etc/hadoop/mapred-site.xml pi@slave01:/usr/share/hadoop/etc/hadoop/mapred-site.xml scp -p /usr/share/hadoop/libexec/hadoop-layout.sh pi@slave02:/usr/share/hadoop/libexec/hadoop-layout.sh scp -p /usr/share/hadoop/etc/hadoop/core-site.xml pi@slave02:/usr/share/hadoop/etc/hadoop/core-site.xml scp -p /usr/share/hadoop/etc/hadoop/hdfs-site.xml pi@slave02:/usr/share/hadoop/etc/hadoop/hdfs-site.xml scp -p /usr/share/hadoop/etc/hadoop/yarn-site.xml pi@slave02:/usr/share/hadoop/etc/hadoop/yarn-site.xml scp -p /usr/share/hadoop/etc/hadoop/mapred-site.xml pi@slave02:/usr/share/hadoop/etc/hadoop/mapred-site.xml
作成できたら、実行します。
pi > $ chmod +x copy-config.sh pi > $ . copy-config.sh
各マシンの設定を統一するため、以後、設定ファイルにミスがあったら、ホスト名:master01のRaspberry Piの設定ファイルを編集してからこのスクリプトファイルを実行するようにします。
スレーブの設定
ホスト名:master01のRaspberry Piのみで実行します。
クラスタのマスタ用マシンにスレーブ用マシンのホストを教えるために、”/usr/share/hadoop/etc/hadoop/slaves”にスレーブ用マシンのホストを記述します。
pi > $ vim /usr/share/hadoop/slaves #localhost slave01 slave02
以上で設定ファイルの編集は終了です。長かった。。。
HDFSの起動
ホスト名:master01のRaspberry Piのみで実行します。
HDFSをフォーマットするために、以下を実行します。
pi > $ su -l hdfs hdfs > $ /usr/share/hadoop/bin/hdfs namenode -format ... hdfs > exit
フォーマットの実行時に色々ログが流れていきますが、最後の方に
INFO common.Storage: Storage directory /usr/share/hdfs/namenode has been successfully formatted.
と表示されていればOKです。このフォーマットは、初めてHDFSを起動させるときだけ実行します。
続けて、以下を実行します。
pi > $ sudo -i -u hdfs /usr/share/hadoop/sbin/start-dfs.sh Java HotSpot(TM) Client VM warning: You have loaded library /usr/share/hadoop-2.7.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 15/10/10 21:17:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [master01] master01: starting namenode, logging to /usr/share/hdfs/logs/hadoop-hdfs-namenode-master01.out slave01: starting datanode, logging to /usr/share/hdfs/logs/hadoop-hdfs-datanode-slave01.out slave02: starting datanode, logging to /usr/share/hdfs/logs/hadoop-hdfs-datanode-slave02.out Starting secondary namenodes [master01] master01: starting secondarynamenode, logging to /usr/share/hdfs/logs/hadoop-hdfs-secondarynamenode-master01.out Java HotSpot(TM) Client VM warning: You have loaded library /usr/share/hadoop-2.7.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 15/10/10 21:18:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
sudoコマンドを使って、hdfsユーザとして実行しています。上記のような感じでログが出ればまずはOKです。ここで
Starting namenodes on [master01] master01: mkdir: cannot create directory ‘/usr/share/hadoop/logs’: Permission denied master01: chown: cannot access ‘/usr/share/hadoop/logs’: No such file or directory master01: starting namenode, logging to /usr/share/hadoop/logs/hadoop-hdfs-namenode-master01.out ...
のようなログが出ている場合は、ログ出力用の環境変数の設定、もしくはディレクトリの作成がうまくいっていないと思われるので、”Hadoopのインストール”と”環境変数”の設定を見直してみてください。
次に、Web UIでHDFSが正しく起動しているか確認します。ブラウザで”http://(マスタ用Raspberry PiのIPアドレス):50070/”にアクセスしてみてください。

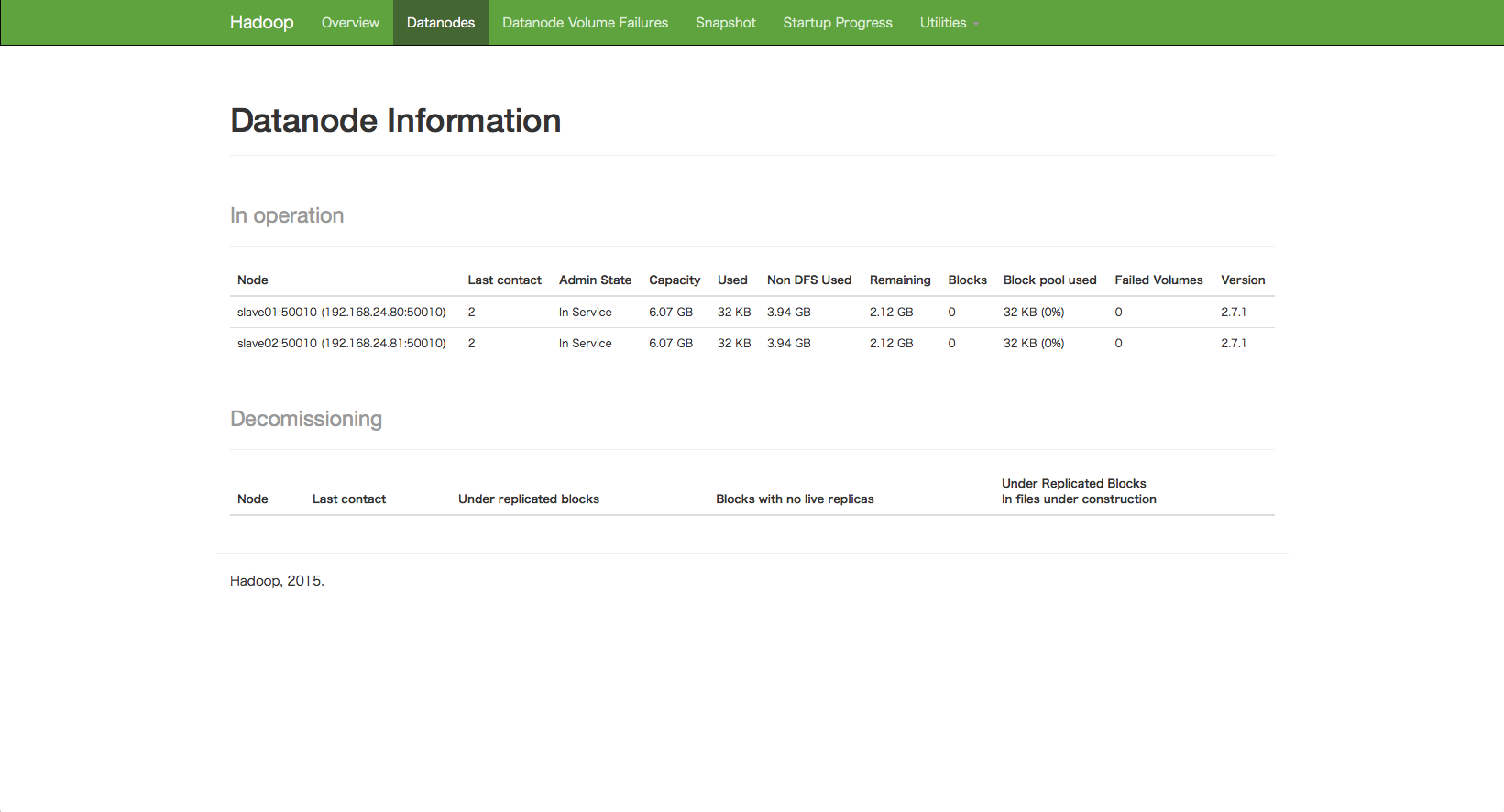
こんな感じで、DataNode2つの情報が見えていればOKです。それが見えない場合は、master01の”/usr/share/hdfs/logs/hadoop-hdfs-namenode-master01.log”やslave01(02)の”/usr/share/hdfs/logs/hadoop-hdfs-datanode-slave01.log”をチェックすると、何が原因で失敗しているかのヒントが得られるハズです。自分の場合は、slave01の方のログで
WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: master01/192.168.24.110:8020
と出ていたので、master01の方で”$ netstat -ln”を実行した結果、8020ポートが”127.0.0.1″で待ち受けている状態になっていることがわかったので、master01の”/etc/hosts”の中にあった”127.0.0.1 master01″の記述をコメントアウトすることで対応しました。
続いてslave01のログに現れた
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool BP-436673220-127.0.1.1-1444467235126 (Datanode Uuid null) service to master01/192.168.24.110:8020 Datanode denied communication with namenode because hostname cannot be resolved (ip=192.168.24.80, hostname=192.168.24.80): DatanodeRegistration(0.0.0.0:50010, datanodeUuid=67c33cf5-7db5-4c66-9d90-e27405a5ab7e, infoPort=50075, infoSecurePort=0, ipcPort=50020, storageInfo=lv=-56;cid=CID-42ca0397-2ffd-4080-bccf-98251237d63d;nsid=1315839620;c=0)
というログに対しては、このあたりを参考にさせていただいた結果、”hdfs-site.xml”に以下のプロパティを追加することで解決しました。
<property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property>
ただ、この解決方法が本当に正しい解決方法なのかどうかは、すみません、勉強不足なのでわかりません(”192.168.24.80″という、設定した覚えのないIPアドレスが、どこから出てきたのかわからない)。
とりあえず、先に進みます。この後必要になるHDFSのディレクトリを、ここで作ってしまいます。master01のマシンで以下を実行します。
pi > $ su -l hdfs hdfs > $ /usr/share/hadoop/bin/hdfs dfs -mkdir /user hdfs > $ /usr/share/hadoop/bin/hdfs dfs -mkdir /user/pi hdfs > $ /usr/share/hadoop/bin/hdfs dfs -chown pi /user/pi hdfs > $ /usr/share/hadoop/bin/hdfs dfs -chgrp users /user/pi hdfs > $ /usr/share/hadoop/bin/hdfs dfs -mkdir /tmp hdfs > $ /usr/share/hadoop/bin/hdfs dfs -chgrp users /tmp hdfs > $ /usr/share/hadoop/bin/hdfs dfs -chmod 777 /tmp hdfs > $ /usr/share/hadoop/bin/hdfs dfs -chmod +t /tmp hdfs > $ exit
YARNの起動
ホスト名:master01のRaspberry Piのみで実行します。
pi > $ sudo -i -u yarn /usr/share/hadoop/sbin/start-yarn.sh
Web UIでYARNが正しく起動しているか確認します。ブラウザで”http://(マスタ用Raspberry PiのIPアドレス):8088/”にアクセスしてみてください。

こんな感じで、”Active Nodes”が2になっていればOKです。
Job History Serverの起動
ホスト名:master01のRaspberry Piのみで実行します。
pi > $ sudo -i -u mapred /usr/share/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
Web UIでJob History Serverが正しく起動しているか確認します。ブラウザで”http://(マスタ用Raspberry PiのIPアドレス):19888/”にアクセスしてみてください。

こんな感じのUIが表示されていればOKです。
動作確認
おつかれさまでした。いよいよ動作確認に入ります。以下、ホスト名:master01のRaspberry Pi上での操作です。
まずは、アプリの実行ユーザでちゃんとHDFSにアクセスできるかどうかの確認です。
pi > $ /usr/share/hadoop/bin/hdfs dfs -ls /user ... Found 1 items drwxr-xr-x - pi users 0 2015-10-10 22:14 /user/pi
問題なさそうです。次に、YARNの動作確認です。
pi > $ /usr/share/hadoop/bin/hadoop jar /usr/share/hadoop/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.1.jar org.apache.hadoop.yarn.applications.distributedshell.Client --jar /usr/share/hadoop/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.1.jar --shell_command date --num_containers 2 --master_memory 512 ... 15/10/10 22:48:27 INFO distributedshell.Client: Application completed successfully
これも問題なさそうです。
最後に、MapReduceの動作確認です。
pi > $ /usr/share/hadoop/bin/hadoop jar /usr/share/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar pi 10 1000 Number of Maps = 10 Samples per Map = 1000 Java HotSpot(TM) Client VM warning: You have loaded library /usr/share/hadoop-2.7.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 15/10/11 10:38:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Wrote input for Map #0 Wrote input for Map #1 Wrote input for Map #2 Wrote input for Map #3 Wrote input for Map #4 Wrote input for Map #5 Wrote input for Map #6 Wrote input for Map #7 Wrote input for Map #8 Wrote input for Map #9 Starting Job 15/10/11 10:39:07 INFO client.RMProxy: Connecting to ResourceManager at master01/192.168.24.110:8032 15/10/11 10:39:10 INFO input.FileInputFormat: Total input paths to process : 10 15/10/11 10:39:10 INFO mapreduce.JobSubmitter: number of splits:10 15/10/11 10:39:11 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1444527340872_0001 15/10/11 10:39:14 INFO impl.YarnClientImpl: Submitted application application_1444527340872_0001 15/10/11 10:39:14 INFO mapreduce.Job: The url to track the job: http://master01:8088/proxy/application_1444527340872_0001/ 15/10/11 10:39:14 INFO mapreduce.Job: Running job: job_1444527340872_0001 15/10/11 10:39:53 INFO mapreduce.Job: Job job_1444527340872_0001 running in uber mode : false 15/10/11 10:39:53 INFO mapreduce.Job: map 0% reduce 0% 15/10/11 10:40:17 INFO mapreduce.Job: map 20% reduce 0% 15/10/11 10:40:39 INFO mapreduce.Job: map 20% reduce 7% 15/10/11 10:42:21 INFO mapreduce.Job: map 27% reduce 7% 15/10/11 10:42:32 INFO mapreduce.Job: map 30% reduce 7% 15/10/11 10:42:35 INFO mapreduce.Job: map 70% reduce 7% 15/10/11 10:42:35 INFO mapreduce.Job: Task Id : attempt_1444527340872_0001_m_000006_0, Status : FAILED Container killed on request. Exit code is 137 Container exited with a non-zero exit code 137 Killed by external signal 15/10/11 10:42:36 INFO mapreduce.Job: map 80% reduce 7% 15/10/11 10:42:39 INFO mapreduce.Job: map 80% reduce 27% 15/10/11 10:42:39 INFO mapreduce.Job: Task Id : attempt_1444527340872_0001_m_000005_0, Status : FAILED Exception from container-launch. Container id: container_1444527340872_0001_01_000007 Exit code: 1 Stack trace: ExitCodeException exitCode=1: at org.apache.hadoop.util.Shell.runCommand(Shell.java:545) at org.apache.hadoop.util.Shell.run(Shell.java:456) at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:722) at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:211) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:744) Container exited with a non-zero exit code 1 15/10/11 10:43:03 INFO mapreduce.Job: map 100% reduce 27% 15/10/11 10:43:05 INFO mapreduce.Job: map 100% reduce 100% 15/10/11 10:43:07 INFO mapreduce.Job: Job job_1444527340872_0001 completed successfully 15/10/11 10:43:08 INFO mapreduce.Job: Counters: 51 File System Counters FILE: Number of bytes read=226 FILE: Number of bytes written=1279388 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=2560 HDFS: Number of bytes written=215 HDFS: Number of read operations=43 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Failed map tasks=2 Launched map tasks=12 Launched reduce tasks=1 Other local map tasks=2 Data-local map tasks=10 Total time spent by all maps in occupied slots (ms)=1336104 Total time spent by all reduces in occupied slots (ms)=166153 Total time spent by all map tasks (ms)=1336104 Total time spent by all reduce tasks (ms)=166153 Total vcore-seconds taken by all map tasks=1336104 Total vcore-seconds taken by all reduce tasks=166153 Total megabyte-seconds taken by all map tasks=342042624 Total megabyte-seconds taken by all reduce tasks=42535168 Map-Reduce Framework Map input records=10 Map output records=20 Map output bytes=180 Map output materialized bytes=280 Input split bytes=1380 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=280 Reduce input records=20 Reduce output records=0 Spilled Records=40 Shuffled Maps =10 Failed Shuffles=0 Merged Map outputs=10 GC time elapsed (ms)=60421 CPU time spent (ms)=41720 Physical memory (bytes) snapshot=1619771392 Virtual memory (bytes) snapshot=5292019712 Total committed heap usage (bytes)=1230282752 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1180 File Output Format Counters Bytes Written=97 Job Finished in 241.739 seconds Estimated value of Pi is 3.14080000000000000000
何やらエラーっぽいものが出ていますが、円周率の計算までは一応終わったようです。

YARNのUIでもStateがFINISHEDになっていますし、

Job History Serverにも記録が残っています(上の画像は2回実行した後の画面です)。
。。。ということで、無事(ではないかもしれませんが)、MapReduceの動作確認まで完了しました。あー疲れた!
最後に、クラスタの起動と終了を一発で行うためのスクリプトを書いておきます。
pi > $ vim start-cluster.sh #!/bin/bash #Start HDFS sudo -i -u hdfs /usr/share/hadoop/sbin/start-dfs.sh #Start YARN sudo -i -u yarn "/usr/share/hadoop/sbin/start-yarn.sh #Start the MR Job History Server sudo -i -u mapred /usr/share/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver pi > $ chmod +x start-cluster.sh
pi > $ vim stop-cluster.sh #!/bin/bash #Stop HDFS sudo -i -u hdfs /usr/share/hadoop/sbin/stop-dfs.sh #Stop YARN sudo -i -u yarn "/usr/share/hadoop/sbin/stop-yarn.sh #Stop the MR Job History Server sudo -i -u mapred /usr/share/hadoop/sbin/mr-jobhistory-daemon.sh stop historyserver pi > $ chmod +x stop-cluster.sh
これで以後は、クラスタのマスタ用のRaspberry Piで
pi > $ . start-cluster.sh pi > $ . stop-cluster.sh
を実行すれば、クラスタの一発起動&終了ができます。
というわけで、Raspberry Pi 2 x 4台(実質は3台)でHadoop 2.x系のクラスタを構築し、MapReduceの動作確認までできました。
もちろんこれ、実用性は皆無なのですが、Hadoopの環境構築のお勉強と、NamaNodeとResourceManagerを分けてもちゃんと動かせるのかとか、色々試してみるのにはお手軽な環境だと思います。