Raspberry Pi上でHadoopクラスタを構築する 〜インストールから擬似分散モードのテストまで〜
今回はお勉強モードです。
普段のお仕事の中で並列分散処理基盤と関わることがあって、それで以前にRaspberry Pi上でのSpark環境構築やらStorm環境構築やらをやったことがあるのですが、並列分散処理基盤の元祖とも言えるHadoopについては、ほとんどノータッチでやってきてしまいました。
多分これからはHadoopよりSparkを使うことの方が多くなってくる気はしているのですが、Sparkを使いこなしていく中で、クラスタマネージャとしてYARNを使わなくてはいけないときがくるかもしれません。
ということで、一回本腰を入れて、Hadoop(特にYARN)を理解するための環境構築をやってみようと思います。利用するのは、おなじみRaspberry Pi 2 Type Bです。
あと、Hadoopについては本当に一度も触ったことがない(本を少し読んだ程度の知識があるだけ)ので、以下の環境構築ではだいぶ無駄なことをしている可能性があります。あくまで参考程度にご覧いただければと思います(CDHとか言うのをちらほら見かけるのですが、まだちゃんと理解していないので今回は使っていません)。
とりあえず、Raspberry Piにhadoop検証用のユーザ”hadoop”を作ることにします。
$ sudo adduser hadoop $ sudo usermod -G sudo hadoop
sudoも使えるようにしています。設定したら、リブートしてhadoopユーザで再ログインします。
次に、本家のダウンロードページから、最新安定版のバイナリ版をダウンロードしてきます。これを書いている時点(2015/9/22)では、2.7.1が最新のようです。
$ wget http://ftp.riken.jp/net/apache/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz $ tar xzvf hadoop-2.7.1.tar.gz
解凍も一緒にやってしまっています。
さて、ここからが本題です。とりあえず、本家のGetting Startedを読むと、「まずはSingle Node Setup、できたらCluster Setupに行け」と書かれているので、素直にSingle Node Setupから始めます。
まず環境変数JAVA_HOMEを設定する必要があります。最新のRaspbian OSは始めからJavaがインストールされていてとても素敵なのですが、それゆえにJAVA_HOMEは意識したことがありませんでした。
調べたところ、以下に書いてくれていました。ありがたや。
ということで、 “~/.bashrc”に以下を記述します。
export JAVA_HOME="/usr/lib/jvm/jdk-8-oracle-arm-vfp-hflt" export PATH=$PATH:$JAVA_HOME/bin
書けたら”$ source .bashrc”でもいいのですが、起動時にちゃんと設定されているかを確認したいので、一度rebootします。で、
$ echo $JAVA_HOME /usr/lib/jvm/jdk-8-oracle-arm-vfp-hflt
確認OK。
ちなみにこちらによると、Hadoop 2.7.1はJava 1.7以上が求められるようですが、Raspbianは始めから1.8が入っています。素敵。また、2.7.1からAzureのBlobもファイルストレージとしてサポートするようになったとのこと。これは今回関係ありませんが、個人的にはメモしておく必要がありそうです。
さて、ここからは以下の3つの動作モードを選択することになります。
- ローカルモード(Local (Standalone) Mode)
- 擬似分散モード(Pseudo-Distributed Mode)
- 完全分散モード(Fully-Distributed Mode)
現状は1台しかセットアップしていないので、上の2つから試していきます。
まずはローカルモードから。これはHDFSを利用しないため、HDFSのマスターサーバ(NameNode)、スレーブサーバ(DataNode)の両プロセスが起動せず、従ってMapReduceの動作検証のみを目的としたモードなのだとか。
先ほど解凍したHadoopのディレクトリ(今回は”hadoop-2.7.1″)に移動したら、ここに記載の通りにコマンドを打ち込みます。
$ mkdir input $ cp etc/hadoop/*.xml input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input output 'dfs[a-z.]+' .....(大量のログ)..... $ cat output/* 1 dfsadmin
…うん、何か動いたようですが、よくわかりません。おそらく、サンプルの中にある”grep”というクラスを実行したものと思われます(そのあとの3つは”grep”サンプルの3つの引数)。
とりあえず動いていることは動いているようなので、先に進みます。次は擬似分散モードで。こちらはHDFSを利用するので、1つのマシン上でNameNodeプロセスとDataNodeプロセスが起動するのだとか。
まずは”etc/hadoop/core-site.xml“の編集から。これは、Hadoop共通の設定を記述するものだそう。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
“core-site.xml”に限らず、Hadoopの.xmlファイルは上記のようにconfigurationタグの中に、nameプロパティとvalueプロパティを持つpropertyタグを入れ込んで設定していく模様。
ローカルモードのときは”fs.defaultFS”プロパティの設定は不要でしたが、今回はHDFSを利用するので、ちゃんとvalueを設定してやります。ちなみに”fs.defaultFS”プロパティを設定するのはHadoop 2.x系からで、1.x系では代わって”fs.default.name”を使用していた模様(設定するvalueは同じ)。
上記はvalueのURIにhdfsスキームを持つ値を設定することで、ローカルファイルシステムではなくHDFSを使うことを宣言しています。で、ポート番号”9000″で、HDFSのNameNode(HDFSのマスターサーバ)が待ち受けるようにしていると。
続いて、”etc/hadoop/hdfs-site.xml“の編集です。こちらはHDFSの挙動に関する設定を記述するものなのだそうです。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
HDFSのデフォルトのレプリケーション数(データを複製するDataNodeの数)は3らしいのですが、擬似分散モードではDataNodeのプロセスが一つ立ち上がるだけなので、レプリケーション数を1に変更してやる必要があります。これが”dfs.replication”設定の意味だそうです。
さて、YARNを使ってMapReruceのジョブを実行させたい場合は、さらにもう二つほど設定ファイルを記述してやらなくてはいけません。まずは”etc/hadoop/mapred-site.xml“。”etc/hadoop/”の下に”mapred-site.xml.template”があるので、これを”mapred-site.xml”としてコピーしたものを編集していきます。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
これで、MapReduceプログラムがYARN環境(ResourceManagerとNodeManager上)で動作するとのこと。valueには他に”local”や”classic”などが設定できる模様。
あと一つ、”etc/hadoop/yarn-site.xml”です。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
少なくとも昔はこれを書いておかないとMapReduceが動作しなかったらしいのですが、今はどうなっているのか、ちょっと不明です。
さて、これで.xml系の設定は以上です。次にsshの設定です。複数のNodeでクラスタを構成する際にはパスフレーズなしでssh接続できなきゃいけないのは直感的にわかるのですが、自分自身(localhost)に対しても同じようにパスフレーズなしでssh接続できるようにしなきゃいけないのは、ちょっと不思議な感じがします。
まずは確認。
$ ssh localhost
普通にパスワードを要求されてしまいましたので、パスフレーズなしでアクセスできるよう、以下を実行します。
$ ssh-keygen $ ssh-copy-id localhost
“ssh-keygen”実行時にパスフレーズの入力を要求されますが、全部空のままEnterでOKです。これでもう一回”$ ssh localhost”を実行すると、パスフレーズなしでアクセスできることが確認できるハズです。
以上、ようやく準備ができたので、実行していきます。まず、NameNodeが管理するメタデータ領域のフォーマット。これは、HDFSのプロセスを立ち上げる前に必要な処理だそうです。
$ bin/hdfs namenode -format 15/09/22 23:03:54 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = raspiA/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.1 .....(中略)..... /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at raspiA/127.0.1.1 ************************************************************/
続いて、HDFSのNameNodeデーモンとDataNodeデーモンの起動です。
$ sbin/start-dfs.sh Java HotSpot(TM) Client VM warning: You have loaded library /home/hadoop/hadoop-2.7.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 15/09/22 23:04:52 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [localhost] localhost: Error: JAVA_HOME is not set and could not be found. localhost: Error: JAVA_HOME is not set and could not be found. Starting secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. ECDSA key fingerprint is 29:99:36:b8:e5:65:2d:e0:f8:a0:26:ef:37:84:d4:8e. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts. 0.0.0.0: Error: JAVA_HOME is not set and could not be found. Java HotSpot(TM) Client VM warning: You have loaded library /home/hadoop/hadoop-2.7.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 15/09/22 23:05:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
なんかエラーが出てます。”localhost: Error: JAVA_HOME is not set and could not be found.”。
試しに”etc/hadoop/hadoop-env.sh”の中のJAVA_HOMEのexportのところを、以下のようにパスをハードコーディングするように修正して再度実行したところ、うまくいきました。
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/jvm/jdk-8-oracle-arm-vfp-hflt
再実行結果。
$ sbin/start-dfs.sh Java HotSpot(TM) Client VM warning: You have loaded library /home/hadoop/hadoop-2.7.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 15/09/22 23:23:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-namenode-raspiA.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-datanode-raspiA.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-secondarynamenode-raspiA.out Java HotSpot(TM) Client VM warning: You have loaded library /home/hadoop/hadoop-2.7.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 15/09/22 23:23:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
うーん、元々の”etc/hadoop/hadoop-env.sh”を見てみると、ハードコーディングじゃなくてもちゃんと環境変数のJAVA_HOMEを取得してくれそうな気がするのだけれど。。。sshで入ると.bashrcが読み込まれないのかな。すみません、勉強不足ですが、とりあえず先に進みます。
NameNodeのWebインタフェースが動作しているかを確認します。ブラウザで”http://(RaspberryPiのIPアドレス):50070/”にアクセスすると、こんな感じの管理画面が出てきます。

確認ができたら、MapReduceのジョブを実行するためのHDFSディレクトリを作成します。
$ bin/hdfs dfs -mkdir -p /user/<username> $ bin/hdfs dfs -ls /user
mkdirには-pオプションをつけて、親ディレクトリもまとめて作成するようにしています。で、lsオプションでちゃんとディレクトリができているかを確認しています。ちなみに、hdfsのコマンドのオプションはこちらにすべて書かれています。色々調べていると、”dfs”の部分が”hdfs”だったり”fs”だったりすることがありますが、基本的にどれも同意語らしいので、とりあえず気にせず進みます。
これでHDFS側の手続きは完了です。あとはYARN側の手続きです。ResourceManagerとNodeManagerのデーモンを起動させます。
$ sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.7.1/logs/yarn-hadoop-resourcemanager-raspiA.out localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.7.1/logs/yarn-hadoop-nodemanager-raspiA.out
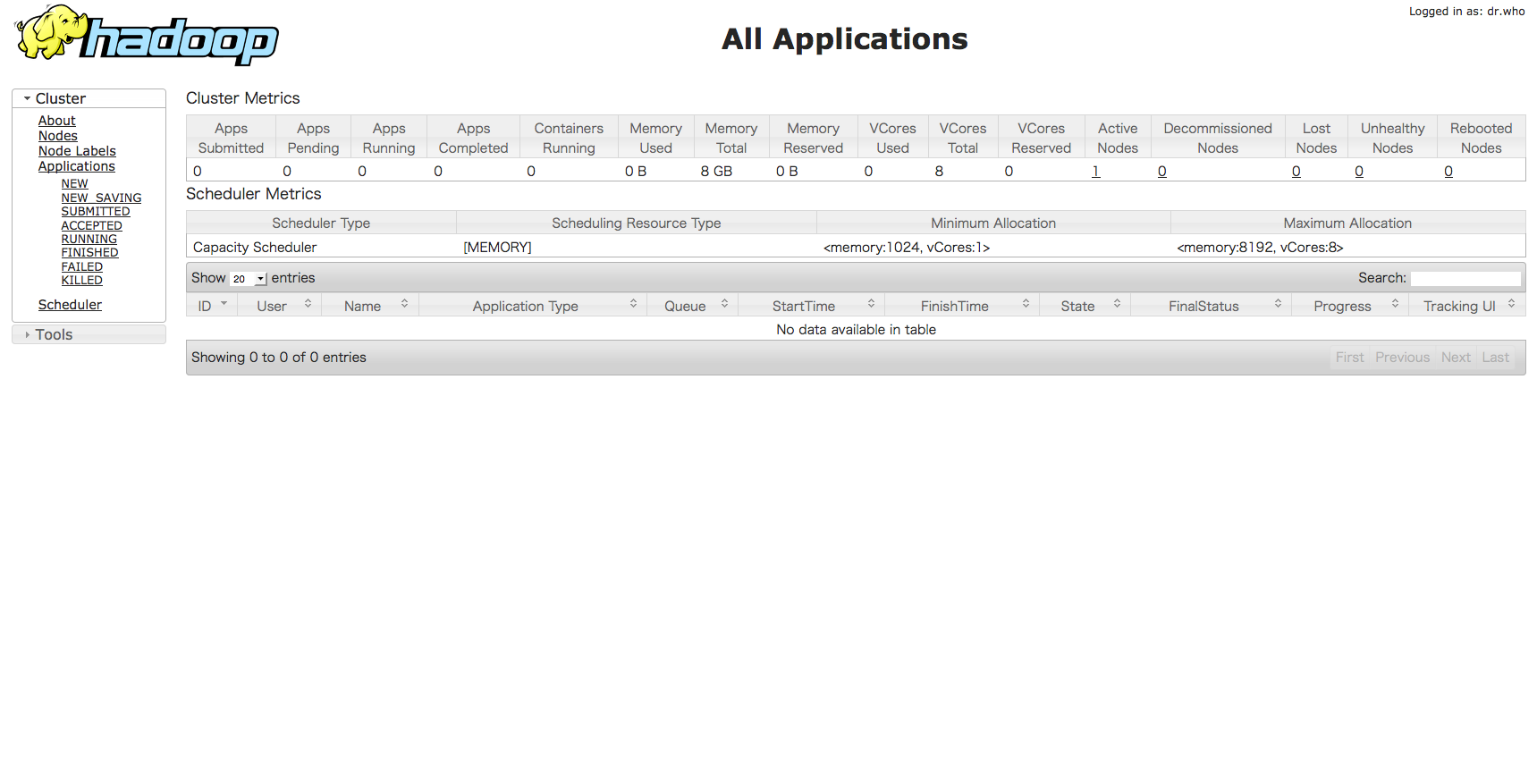
今度はResourceManagerのWebインタフェースが動作しているかを確認します。ブラウザで”http://(RaspberryPiのIPアドレス):8088/”にアクセスすると、こんな感じの管理画面が出てきます。
確認ができたら、いよいよMapReduceジョブを実行させます。今回はローカルモードと同じサンプルプログラム(grep)を実行するので 、先にそのための準備をします。
$ bin/hdfs dfs -put etc/hadoop input $ bin/hdfs dfs -ls input
putオプションで、ローカルファイルシステムのディレクトリ(”etc/hadoop”)を、HDFS上にディレクトリ”input”としてコピーしてきています。それから、HDFS上のinputディレクトリの中身がちゃんとあるかを確認しています。
準備ができたら、サンプルを実行します。
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input output 'dfs[a-z.]+' Java HotSpot(TM) Client VM warning: You have loaded library /home/hadoop/hadoop-2.7.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 15/09/23 10:05:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 15/09/23 10:05:29 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 15/09/23 10:05:35 INFO input.FileInputFormat: Total input paths to process : 30 15/09/23 10:05:35 INFO mapreduce.JobSubmitter: number of splits:30 15/09/23 10:05:36 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1442970209569_0001 15/09/23 10:05:38 INFO impl.YarnClientImpl: Submitted application application_1442970209569_0001 15/09/23 10:05:39 INFO mapreduce.Job: The url to track the job: http://raspiA:8088/proxy/application_1442970209569_0001/ 15/09/23 10:05:39 INFO mapreduce.Job: Running job: job_1442970209569_0001 15/09/23 10:06:18 INFO mapreduce.Job: Job job_1442970209569_0001 running in uber mode : false 15/09/23 10:06:18 INFO mapreduce.Job: map 0% reduce 0% 15/09/23 10:11:50 INFO mapreduce.Job: map 3% reduce 0% 15/09/23 10:11:51 INFO mapreduce.Job: map 7% reduce 0% 15/09/23 10:12:11 INFO mapreduce.Job: map 10% reduce 0% 15/09/23 10:13:30 INFO mapreduce.Job: map 13% reduce 0% 15/09/23 10:23:12 INFO mapreduce.Job: map 20% reduce 0% 15/09/23 10:23:13 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000005_0, Status : FAILED Container killed on request. Exit code is 137 Container exited with a non-zero exit code 137 Killed by external signal 15/09/23 10:23:14 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000003_0, Status : FAILED Container killed on request. Exit code is 137 Container exited with a non-zero exit code 137 Killed by external signal 15/09/23 10:23:14 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000004_0, Status : FAILED Error: java.io.IOException: Failed on local exception: java.io.IOException: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/127.0.0.1:54581 remote=localhost/127.0.0.1:9000]; Host Details : local host is: "raspiA/127.0.1.1"; destination host is: "localhost":9000; at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:773) at org.apache.hadoop.ipc.Client.call(Client.java:1480) at org.apache.hadoop.ipc.Client.call(Client.java:1407) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229) at com.sun.proxy.$Proxy13.getBlockLocations(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getBlockLocations(ClientNamenodeProtocolTranslatorPB.java:255) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:483) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy14.getBlockLocations(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.callGetBlockLocations(DFSClient.java:1240) at org.apache.hadoop.hdfs.DFSClient.getLocatedBlocks(DFSClient.java:1227) at org.apache.hadoop.hdfs.DFSClient.getLocatedBlocks(DFSClient.java:1215) at org.apache.hadoop.hdfs.DFSInputStream.fetchLocatedBlocksAndGetLastBlockLength(DFSInputStream.java:303) at org.apache.hadoop.hdfs.DFSInputStream.openInfo(DFSInputStream.java:269) at org.apache.hadoop.hdfs.DFSInputStream.<init>(DFSInputStream.java:261) at org.apache.hadoop.hdfs.DFSClient.open(DFSClient.java:1540) at org.apache.hadoop.hdfs.DistributedFileSystem$3.doCall(DistributedFileSystem.java:303) at org.apache.hadoop.hdfs.DistributedFileSystem$3.doCall(DistributedFileSystem.java:299) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.open(DistributedFileSystem.java:299) at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:767) at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.initialize(LineRecordReader.java:85) at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.initialize(MapTask.java:548) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:786) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Caused by: java.io.IOException: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/127.0.0.1:54581 remote=localhost/127.0.0.1:9000] at org.apache.hadoop.ipc.Client$Connection$1.run(Client.java:682) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657) at org.apache.hadoop.ipc.Client$Connection.handleSaslConnectionFailure(Client.java:645) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:732) at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:370) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1529) at org.apache.hadoop.ipc.Client.call(Client.java:1446) ... 32 more Caused by: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/127.0.0.1:54581 remote=localhost/127.0.0.1:9000] at org.apache.hadoop.net.SocketIOWithTimeout.doIO(SocketIOWithTimeout.java:164) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:161) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:131) at java.io.FilterInputStream.read(FilterInputStream.java:133) at java.io.BufferedInputStream.fill(BufferedInputStream.java:246) at java.io.BufferedInputStream.read(BufferedInputStream.java:265) at java.io.DataInputStream.readInt(DataInputStream.java:387) at org.apache.hadoop.security.SaslRpcClient.saslConnect(SaslRpcClient.java:367) at org.apache.hadoop.ipc.Client$Connection.setupSaslConnection(Client.java:555) at org.apache.hadoop.ipc.Client$Connection.access$1800(Client.java:370) at org.apache.hadoop.ipc.Client$Connection$2.run(Client.java:724) at org.apache.hadoop.ipc.Client$Connection$2.run(Client.java:720) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:719) ... 35 more 15/09/23 10:23:14 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000002_0, Status : FAILED Error: java.io.IOException: Failed on local exception: java.io.IOException: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/127.0.0.1:54572 remote=localhost/127.0.0.1:9000]; Host Details : local host is: "raspiA/127.0.1.1"; destination host is: "localhost":9000; at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:773) at org.apache.hadoop.ipc.Client.call(Client.java:1480) at org.apache.hadoop.ipc.Client.call(Client.java:1407) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229) at com.sun.proxy.$Proxy13.getBlockLocations(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getBlockLocations(ClientNamenodeProtocolTranslatorPB.java:255) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:483) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy14.getBlockLocations(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.callGetBlockLocations(DFSClient.java:1240) at org.apache.hadoop.hdfs.DFSClient.getLocatedBlocks(DFSClient.java:1227) at org.apache.hadoop.hdfs.DFSClient.getLocatedBlocks(DFSClient.java:1215) at org.apache.hadoop.hdfs.DFSInputStream.fetchLocatedBlocksAndGetLastBlockLength(DFSInputStream.java:303) at org.apache.hadoop.hdfs.DFSInputStream.openInfo(DFSInputStream.java:269) at org.apache.hadoop.hdfs.DFSInputStream.<init>(DFSInputStream.java:261) at org.apache.hadoop.hdfs.DFSClient.open(DFSClient.java:1540) at org.apache.hadoop.hdfs.DistributedFileSystem$3.doCall(DistributedFileSystem.java:303) at org.apache.hadoop.hdfs.DistributedFileSystem$3.doCall(DistributedFileSystem.java:299) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.open(DistributedFileSystem.java:299) at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:767) at org.apache.hadoop.mapred.MapTask.getSplitDetails(MapTask.java:356) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:754) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Caused by: java.io.IOException: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/127.0.0.1:54572 remote=localhost/127.0.0.1:9000] at org.apache.hadoop.ipc.Client$Connection$1.run(Client.java:682) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657) at org.apache.hadoop.ipc.Client$Connection.handleSaslConnectionFailure(Client.java:645) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:732) at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:370) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1529) at org.apache.hadoop.ipc.Client.call(Client.java:1446) ... 31 more Caused by: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/127.0.0.1:54572 remote=localhost/127.0.0.1:9000] at org.apache.hadoop.net.SocketIOWithTimeout.doIO(SocketIOWithTimeout.java:164) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:161) at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:131) at java.io.FilterInputStream.read(FilterInputStream.java:133) at java.io.BufferedInputStream.fill(BufferedInputStream.java:246) at java.io.BufferedInputStream.read(BufferedInputStream.java:265) at java.io.DataInputStream.readInt(DataInputStream.java:387) at org.apache.hadoop.security.SaslRpcClient.saslConnect(SaslRpcClient.java:367) at org.apache.hadoop.ipc.Client$Connection.setupSaslConnection(Client.java:555) at org.apache.hadoop.ipc.Client$Connection.access$1800(Client.java:370) at org.apache.hadoop.ipc.Client$Connection$2.run(Client.java:724) at org.apache.hadoop.ipc.Client$Connection$2.run(Client.java:720) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:719) ... 34 more 15/09/23 10:23:14 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000007_0, Status : FAILED AttemptID:attempt_1442970209569_0001_m_000007_0 Timed out after 600 secs 15/09/23 10:23:14 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000006_0, Status : FAILED AttemptID:attempt_1442970209569_0001_m_000006_0 Timed out after 600 secs 15/09/23 10:23:15 INFO mapreduce.Job: map 7% reduce 0% 15/09/23 10:23:19 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000000_0, Status : FAILED Container killed on request. Exit code is 137 Container exited with a non-zero exit code 137 Killed by external signal 15/09/23 10:23:20 INFO mapreduce.Job: map 3% reduce 0% 15/09/23 10:24:36 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000004_1, Status : FAILED Container killed on request. Exit code is 137 Container exited with a non-zero exit code 137 Killed by external signal 15/09/23 10:24:37 INFO mapreduce.Job: map 13% reduce 0% 15/09/23 10:24:51 INFO mapreduce.Job: map 20% reduce 0% 15/09/23 10:25:43 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000008_0, Status : FAILED Container killed on request. Exit code is 137 Container exited with a non-zero exit code 137 Killed by external signal 15/09/23 10:25:46 INFO mapreduce.Job: map 27% reduce 0% 15/09/23 10:25:52 INFO mapreduce.Job: map 30% reduce 0% 15/09/23 10:26:06 INFO mapreduce.Job: map 33% reduce 0% 15/09/23 10:26:08 INFO mapreduce.Job: map 33% reduce 11% 15/09/23 10:26:33 INFO mapreduce.Job: map 40% reduce 11% 15/09/23 10:26:33 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000008_1, Status : FAILED Exception from container-launch. Container id: container_1442970209569_0001_01_000023 Exit code: 1 Stack trace: ExitCodeException exitCode=1: at org.apache.hadoop.util.Shell.runCommand(Shell.java:545) at org.apache.hadoop.util.Shell.run(Shell.java:456) at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:722) at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:211) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:744) Container exited with a non-zero exit code 1 15/09/23 10:26:33 INFO mapreduce.Job: Task Id : attempt_1442970209569_0001_m_000012_0, Status : FAILED Exception from container-launch. Container id: container_1442970209569_0001_01_000024 Exit code: 1 Stack trace: ExitCodeException exitCode=1: at org.apache.hadoop.util.Shell.runCommand(Shell.java:545) at org.apache.hadoop.util.Shell.run(Shell.java:456) at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:722) at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:211) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:744) Container exited with a non-zero exit code 1 15/09/23 10:26:34 INFO mapreduce.Job: map 40% reduce 13% 15/09/23 10:26:42 INFO mapreduce.Job: map 43% reduce 13% 15/09/23 10:26:44 INFO mapreduce.Job: map 43% reduce 14% 15/09/23 10:27:07 INFO mapreduce.Job: map 47% reduce 14% 15/09/23 10:27:08 INFO mapreduce.Job: map 50% reduce 16% 15/09/23 10:27:11 INFO mapreduce.Job: map 50% reduce 17% 15/09/23 10:27:14 INFO mapreduce.Job: map 53% reduce 17% 15/09/23 10:27:16 INFO mapreduce.Job: map 57% reduce 17% 15/09/23 10:27:18 INFO mapreduce.Job: map 60% reduce 19% 15/09/23 10:27:21 INFO mapreduce.Job: map 60% reduce 20% 15/09/23 10:27:44 INFO mapreduce.Job: map 63% reduce 20% 15/09/23 10:27:45 INFO mapreduce.Job: map 67% reduce 20% 15/09/23 10:27:47 INFO mapreduce.Job: map 67% reduce 22% 15/09/23 10:27:50 INFO mapreduce.Job: map 73% reduce 22% 15/09/23 10:27:54 INFO mapreduce.Job: map 73% reduce 24% 15/09/23 10:27:56 INFO mapreduce.Job: map 77% reduce 24% 15/09/23 10:28:00 INFO mapreduce.Job: map 77% reduce 26% 15/09/23 10:28:19 INFO mapreduce.Job: map 80% reduce 26% 15/09/23 10:28:20 INFO mapreduce.Job: map 83% reduce 26% 15/09/23 10:28:22 INFO mapreduce.Job: map 83% reduce 28% 15/09/23 10:28:29 INFO mapreduce.Job: map 90% reduce 28% 15/09/23 10:28:31 INFO mapreduce.Job: map 93% reduce 28% 15/09/23 10:28:32 INFO mapreduce.Job: map 93% reduce 30% 15/09/23 10:28:35 INFO mapreduce.Job: map 93% reduce 31% 15/09/23 10:28:48 INFO mapreduce.Job: map 97% reduce 31% 15/09/23 10:28:49 INFO mapreduce.Job: map 100% reduce 31% 15/09/23 10:28:51 INFO mapreduce.Job: map 100% reduce 67% 15/09/23 10:28:52 INFO mapreduce.Job: map 100% reduce 100% 15/09/23 10:28:53 INFO mapreduce.Job: Job job_1442970209569_0001 completed successfully 15/09/23 10:28:54 INFO mapreduce.Job: Counters: 52 File System Counters FILE: Number of bytes read=345 FILE: Number of bytes written=3590443 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=81605 HDFS: Number of bytes written=437 HDFS: Number of read operations=93 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Failed map tasks=11 Killed map tasks=1 Launched map tasks=42 Launched reduce tasks=1 Other local map tasks=11 Data-local map tasks=31 Total time spent by all maps in occupied slots (ms)=8272389 Total time spent by all reduces in occupied slots (ms)=237626 Total time spent by all map tasks (ms)=8272389 Total time spent by all reduce tasks (ms)=237626 Total vcore-seconds taken by all map tasks=8272389 Total vcore-seconds taken by all reduce tasks=237626 Total megabyte-seconds taken by all map tasks=8470926336 Total megabyte-seconds taken by all reduce tasks=243329024 Map-Reduce Framework Map input records=2096 Map output records=24 Map output bytes=590 Map output materialized bytes=519 Input split bytes=3654 Combine input records=24 Combine output records=13 Reduce input groups=11 Reduce shuffle bytes=519 Reduce input records=13 Reduce output records=11 Spilled Records=26 Shuffled Maps =30 Failed Shuffles=0 Merged Map outputs=30 GC time elapsed (ms)=66247 CPU time spent (ms)=105870 Physical memory (bytes) snapshot=4884897792 Virtual memory (bytes) snapshot=9634127872 Total committed heap usage (bytes)=3657818112 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=77951 File Output Format Counters Bytes Written=437 15/09/23 10:28:55 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 15/09/23 10:28:55 INFO input.FileInputFormat: Total input paths to process : 1 15/09/23 10:28:55 INFO mapreduce.JobSubmitter: number of splits:1 15/09/23 10:28:55 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1442970209569_0002 15/09/23 10:28:55 INFO impl.YarnClientImpl: Submitted application application_1442970209569_0002 15/09/23 10:28:55 INFO mapreduce.Job: The url to track the job: http://raspiA:8088/proxy/application_1442970209569_0002/ 15/09/23 10:28:55 INFO mapreduce.Job: Running job: job_1442970209569_0002 15/09/23 10:29:31 INFO mapreduce.Job: Job job_1442970209569_0002 running in uber mode : false 15/09/23 10:29:31 INFO mapreduce.Job: map 0% reduce 0% 15/09/23 10:29:52 INFO mapreduce.Job: map 100% reduce 0% 15/09/23 10:30:12 INFO mapreduce.Job: map 100% reduce 100% 15/09/23 10:30:13 INFO mapreduce.Job: Job job_1442970209569_0002 completed successfully 15/09/23 10:30:14 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=291 FILE: Number of bytes written=231089 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=569 HDFS: Number of bytes written=197 HDFS: Number of read operations=7 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=16518 Total time spent by all reduces in occupied slots (ms)=17534 Total time spent by all map tasks (ms)=16518 Total time spent by all reduce tasks (ms)=17534 Total vcore-seconds taken by all map tasks=16518 Total vcore-seconds taken by all reduce tasks=17534 Total megabyte-seconds taken by all map tasks=16914432 Total megabyte-seconds taken by all reduce tasks=17954816 Map-Reduce Framework Map input records=11 Map output records=11 Map output bytes=263 Map output materialized bytes=291 Input split bytes=132 Combine input records=0 Combine output records=0 Reduce input groups=5 Reduce shuffle bytes=291 Reduce input records=11 Reduce output records=11 Spilled Records=22 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=994 CPU time spent (ms)=5280 Physical memory (bytes) snapshot=230064128 Virtual memory (bytes) snapshot=624488448 Total committed heap usage (bytes)=137891840 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=437 File Output Format Counters Bytes Written=197
。。。何か間に結構エラーが挟まっていたり、完了まで25分かかったりしていますが、一応最後まで動きました。最後に、結果の確認です。
$ bin/hdfs dfs -cat output/* Java HotSpot(TM) Client VM warning: You have loaded library /home/hadoop/hadoop-2.7.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. 15/09/23 10:47:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 6 dfs.audit.logger 4 dfs.class 3 dfs.server.namenode. 2 dfs.period 2 dfs.audit.log.maxfilesize 2 dfs.audit.log.maxbackupindex 1 dfsmetrics.log 1 dfsadmin 1 dfs.servers 1 dfs.replication 1 dfs.file
一応、出力までちゃんとできた。。。のかな。かなり無理をさせた気がしますが。
実行が終わったら、HDFSのNameNodeとDataNodeのプロセス、YARNのResourceManagerとNodeManagerのプロセスを終了させます。
$ sbin/stop-dfs.sh $ sbin/stop-yarn.sh
ということで、一応YARN上で擬似分散モードのサンプルが動くところまで確認できました。
実はこのあと複数台のRaspberry Piを使って完全分散モードを試みたのですが、ちょっとうまいこといっていません。個人的にはもう少し突き詰めてみたいのですが、ちょっと他に優先しなくてはいけないことがあるので、Raspberry Piを使っての環境構築は一旦ストップします。すみません。